
IP 주소
`IP 주소 (Internet Protocol Address)`는 인터넷에 연결된 기기를 식별하기 위한 고유 주소
집 마다 있는 우편번호 처럼, 네트워크 상에서 데이터를 주고 받기 위해 필요한 위치 정보
❓ IP 주소는 왜 필요하지 ?
기기마다 고유한 주소가 있어야 데이터가 정확한 목적지로 도달 가능
ex) 웹 브라우저로 `naver.com`에 접속하면, 그 요청의 내 IP 주소를 포함한 형태로 전송
1) IPv4 헤더 구조
IPv4 헤더는 기본적으로 20바이트 길이이며, 아래와 같은 필드로 구성되어 있음
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| IHL |Type of Service| Total Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identification |Flags| Fragment Offset |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Time to Live | Protocol | Header Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source IP Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Destination IP Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 바이트 | 필드명 | 크기 (비트) | 설명 |
| 1 | Version | 4 | IP 버전 (IPv4면 4) |
| IHL (Header Length) | 4 | 헤더 길이 (32비트 단위) | |
| 2 | Type of Service (ToS) | 8 | 패킷 우선순위 및 서비스 품질 |
| 3-4 | Total Length | 16 | 전체 패킷 길이 (헤더 + 데이터) |
| 5-6 | Identification | 16 | 조각화된 패킷의 식별 번호 |
| 7 | Flags | 3 | 조각화 제어 (DF, MF 등) |
| Fragment Offset | 13 | 조각의 순서 | |
| 8 | Time to Live (TTL) | 8 | 패킷 생존 시간 (라우터 거칠 때마다 감소) |
| 9 | Protocol | 8 | 상위 계층 프로토콜 (예: TCP=6, UDP=17) |
| 10-11 | Header Checksum | 16 | 헤더 오류 검출용 체크섬 |
| 12-15 | Source IP Address | 32 | 송신자 IP |
| 16-19 | Destination IP Address | 32 | 수신자 IP |
| 20+ | Options + Padding (선택) | 가변 | 확장 옵션 (필요 시만) |
2) TTL (Timt To Live) 필드
IP 패킷이 네트워크에서 살아남을 수 있는 생존 시간 정의 (8비트)
패킷이 네트워크에서 순환하다 무한 루프에 빠지는 것을 방지하는 필드
초기 TTL 값은 OS 별로 상이함 (Linux: 64, Windows: 128)
동작 방식
- 라우터를 지날 때마다 1씩 감소
- 0이 되면 패킷 폐기 ∵ 무한 루프 방지
- 폐기 시 ICMP 메시지 (Time Exceeded)발송
3) IPv4 Checksum VS TCP Checksum
둘 다 오류 검출을 위한 용도이지만, 계산 대상 범위 & 위치가 다름
IPv4 체크섬은 IP 헤더만 검사, 패킷이 전송되는 동안 IP 헤더의 무결성을 확인하는 데 사용

| 항목 | IPv4 Checksum | TCP Checksum |
| 위치 | IP 헤더 내 | TCP 세그먼트 내 |
| 대상 | IP 헤더만 | TCP 헤더 + 데이터 + 의사헤더 |
| 목적 | IP 헤더 오류 검출 | TCP 데이터 전송 오류 검출 |
| 변화 여부 | TTL 등 필드 변화 시 계속 재계산 | 전송 시 한 번 계산 (라우터는 변경 안 함) |
| 사용 여부 | IPv4에 존재, IPv6에서는 제거됨 | TCP에 계속 존재 (IPv6에서도) |
TCP 체크섬과의 차이 ?
- TCP 체크섬은 `헤더 + 데이터 + IP 주소 정보`까지 포함한 의사 헤더 사용
- 이는 패킷 전송 중 발생할 수 있는 더 다양한 오류를 검출하려는 목적
TCP 체크섬은 데이터 오류뿐만 아니라, 전송된 IP 주소의 오류도 확인
👉 더 신뢰성 있는 오류 검출이 가능
❓ 의사 헤더 (pseudo-header)
TCP/UDP 체크섬 계산을 위한 가상의 헤더로, 실제 전송되는 패킷에 포함되지 않지만 체크섬 계산 시 사용
IP 패킷의 IP 주소, 프로토콜 정보가 전송 중의 오류를 감지하는 데 필요한 중요한 부분임
∴ 체크섬 계산 시 이를 함께 고려하는 것
TTL 변경 시 체크섬 재계산 문제
TTL이 감소할 때마다, IPv4 헤더의 체크섬을 다시 계산해야 하는데, 이는 추가적인 계산 비용을 초래.
라우터에서 패킷을 수정할 때마다 체크섬을 매번 다시 계산해야 하기 때문에, 네트워크 성능에 부정적인 영향
IPv6에서는 TTL & Checksum을 제거하고 Hop Limit을 도입 = 더 이상 체크섬을 재계산할 필요X
MAC 주소 (Media Access Control 주소)
물리적 장비에 할당하는, 네트워크에서 각 장치를 고유하게 식별하는 주소
네트워크 카드나 라우터 등 네트워크 장비에 내장된 하드웨어에 설정

물리적 네트워크 장치에 대한 주소이므로 전 세계 어디서나 고유함
| 항목 | MAC 주소 | IP 주소 |
| 용도 | 장비 식별 | 위치 식별 |
| 유형 | 물리적 주소 | 논리적 주소 |
| 고정 여부 | 고정 (보통) | 변경 가능 (DHCP) |
| 형식 | 48비트 16진수 | IPv4 (32비트), IPv6 (128비트) |
| OSI 계층 | 2계층 (데이터 링크) | 3계층 (네트워크) |
홉바이홉 통신
IP 주소를 통해 통신화는 과정을 `홉바이홉 통신`이라고 함
❓ 홉(hop)
건너뛰다 라는 의미, 통신망에서 각 패킷이 여러 개의 라우터를 건너가는 모습을 비유적으로 표현
수많은 서브네트워크 안에 있는 라우터의 라우팅 테이블 IP를 기반으로 패킷을 전달해나가며 라우팅을 수행
👉 최종 목적지까지 패킷 전달

통신 장치에 있는 `라우팅 테이블`의 IP를 통해 시작 주소부터 시작하여,
다음 IP로 계속 이동하는 `라우팅` 과정을 거쳐 패킷이 최종 목적지까지 도달하는 통신 방식을 말함.
라우팅 테이블 (Routing Table)
- 송신지에서 수신지까지 도달하기 위해 사용
- 라우터에 들어가 있는 목적지 정보들과 그 목적지로 가기 위한 방법이 들어있는 리스트
- 게이트웨이와 모든 목적지에 대해 해당 목적지에 도달하기 위해 거쳐야할 다음 라우터 정보 포함
게이트웨이 (Gateway)
서로 다른 통신망, 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 하는 관문 역할을 하는
컴퓨터나 소프트웨어를 두루 일컫는 용어
- 사용자는 인터넷에 접속하기 위해 수많은 게이트웨이를 거쳐야 함.
- 게이트웨이는 서로 다른 네트워크상의 통신 프로토콜을 변환해주는 역할을 함
게이트웨이를 확인하는 방법은 `라우팅 테이블`을 통해 볼 수 있음
❓ 라우팅 테이블은 어떻게 확인하는데?
윈도우에서는 명령 프롬프트에서 `netstat -r` 명령어 실행하여 확인
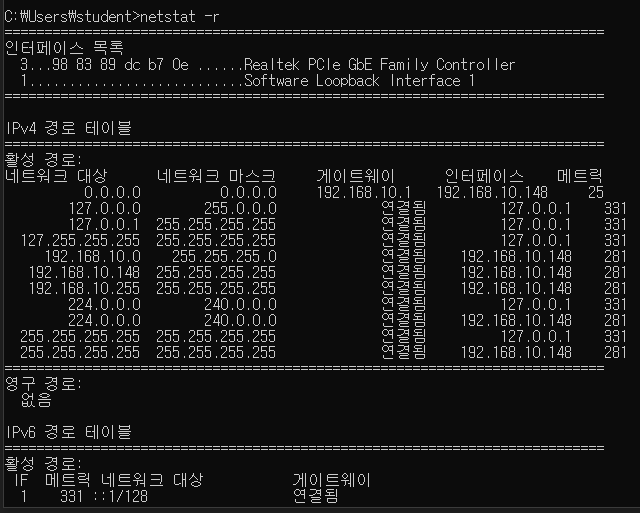
IPv4 경로 테이블, IPv6 경로 테이블 존재 (= 라우팅 테이블)
ARP (Address Resolution Protocol)
컴퓨터 간의 통신은 흔히 IP 주소를 기반으로 통신한다고 말함.
정확히는 IP 주소에서 ARP를 통해 MAC 주소를 찾아 MAC 주소를 기반으로 통신한다.
∴ ARP란 IP 주소로부터 MAC 주소를 구하는, 다리 역할을 하는 프로토콜임
- IP(가상) → MAC(실제`): ARP 사용
- MAC → IP : RAPR 사용
ARP가 주소를 찾는 과정

- 장치 A가 ARP Request 브로드캐스트를 보내서 IP 주소인 `127.70.80.3`에 해당하는 MAC 주소 찾음
- 해당 주소에 맞는 장치 B가 ARP Reply 유니캐스트를 통해 MAC 주소 반환
📌 브로드캐스트 & 유니캐스트
`브로드캐스트`: 송신 호스트가 전송한 데이터가 네트워크에 연결된 모든 호스트에 전송되는 방식
`유니캐스트`: 고유 주소로 식별된 하나의 네트워크 목적지에 1:1로 데이터를 전송하는 방식
IP 주소 체계
IP 주소는 IPv6와 IPv4로 나뉜다.
- IPv4: 32비트를 8비트 단위로 점을 찍어 표기, `123.45.67.89` 형식
- IPv6: 64비트를 16비트 단위로 점을 찍어 표기, `2001:db8::ff00:42:8654` 형식
추세는 IPv6로 가고 있지만 현재 가장 많이 쓰이는 주소 체계는 IPv4 형식임.
📌 IPv6 64비트? 128비트?
IPv6 주소는 전체적으로 128비트로 앞의 64비트를 네트워크 식별에, 뒤의 64비트를 인터페이스 식별자에 사용함
그래서 인터페이스 ID가 64비트라는 점 때문에 ‘IPv6가 64비트 주소체계’라는 표현이 나오지만,
전체 주소 길이는 128비트
- 네트워크 프리픽스: 네트워크 구간 식별 (라우팅에 사용)
- 인터페이스 식별자: 네트워크 내의 장치 식별 (호스트 주소)
IPv6 헤더 구조 (고정 40 바이트)
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| Traffic Class | Flow Label |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Length | Next Header | Hop Limit |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Address (128 bits) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Destination Address (128 bits) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+👉 TTL = Hop Limit
클래스 기반 할당 방식
IP 주소 체계는 발전해오고 있으며 처음에는 A, B, C, D, E 다섯 개의 클래스로 구분하는 클래스 기반 할당방식 사용
앞단을 네트워크 주소, 뒷단을 컴퓨터에 부여하는 주소인 호스트 주소로 놓아서 사용

- 클래스 A, B, C: 일대일 통신으로 사용
- 클래스 D: 멀티캐스트 통신
- 클래스 E: 앞으로 사용할 예비용

맨 왼쪽에 있는 비트를 `구분 비트`라고 함
- 클래스 A의 구분 비트: 0
- 클래스 B의 구분 비트: 10
- 클래스 C의 구분 비트: 110
👉 구분 비트를 통해 클래스 간의 IP가 나뉘어짐
네트워크의 첫 번째 주소는 네트워크 주소로 사용,
가장 마지막 주소는 브로드캐스트용 주소로 네트워크에 속해있는 모든 데이터를 보낼때 사용
예시) 클래스 A로 12.0.0.0이란 네트워크 부여
호스트 주소: 12.0.0.1 ~ 12.255.255.254 = 사용 가능
12.0.0.0 (네트워크 주소), 12.255.255.255 (브로드캐스트 주소) = 사용 불가능
클래스 기반 할당 방식은 사용하는 주소보다 버리는 주소가 많은 단점이 있음
이를 해소하기 위해 DHCP, IPv6와 NAT 등장
❓ 버리는 주소가 많다? 👇🏻
클래스 기반 할당 방식은 고정된 크기의 주소 블록을 제공하기 때문에
실제 필요보다 훨씬 많은 주소를 할당받게 되고, 그 중 대부분은 사용하지 못하고 '버리는 주소'가 됨
| 클래스 | 주소 범위 | 호스트 수 (이론) |
| A | /8 (예: 10.0.0.0) | 약 1,670만 개 |
| B | /16 (예: 172.16.0.0) | 약 65,000 개 |
| C | /24 (예: 192.168.1.0) | 256개 (실사용 254개) |
문제 시나리오
어떤 기업이 1,000개 정도의 IP 주소가 필요한 상황
클래스 C로는?
- 한 C 클래스(/24)는 256개 IP 제공
- 256개로는 부족하니 5개 C 클래스가 필요 → 하지만 연속된 5개를 할당받는 건 어렵고 비효율적
클래스 B를 받으면?
- B 클래스(/16)는 65,534개 IP 제공
- 기업은 1,000개만 필요하므로, 나머지 64,000개 주소는 사용하지 않고 버림
이렇게 필요보다 너무 큰 덩어리를 받게 되어 수많은 IP가 미사용 상태로 방치됨
이게 바로 "주소 낭비", 즉 "버리는 주소가 많다"는 말
| 문제점 | 설명 |
| 고정된 블록 크기 | 필요한 만큼 못 나눔 (예: 1,000개 필요해도 65,000개 줌) |
| 주소 낭비 | 대부분 미사용 상태로 남음 |
| 라우팅 비효율 | 라우터는 각 클래스 단위로 경로를 기억해야 해서 라우팅 테이블이 커짐 |
| 인터넷 주소 고갈 가속 | 낭비가 심해 주소 소모가 빠름 |
👉 CIDR의 도입
DHCP (Dynamic Host Configuration Protocol)
- IP주소 및 기타 통신 매개변수를 자동으로 할당하기 위한 네트워크 관리 프로토콜
- 네트워크 장치의 IP 주소를 수동으로 설정X, 인터넷에 접속할 때마다 자동으로 IP 주소 할당
- 많은 라우터 & 게이트웨이 장비에 DHCP 기능 O → 대부분 가정용 네트워크에서 IP 주소 할당
NAT (Network Address Translation)
패킷이 라우팅 장치를 통해 전송되는 동안 패킷의 IP 주소 정보를 수정하여, IP 주소를 다른 주소로 매핑하는 방법
IPv4 주소 체계만으로는 많은 주소들을 감당하지 못함
👉 NAT로 `공인 IP` 와 `사설 IP` 로 나누어서 많은 주소를 처리

- 두리, 복남이, 덕구는 `192.168.0.xxx`를 기반으로 각각의 다른 IP 소유 = 사설 IP
- NAT 장치를 통해 하나의 공인 IP (121.165.151.200)으로 외부 인터넷에 요청 가능
NAT 장치를 통해 사설 IP와 공인 IP 간 변환 가능
CIDR (Class Inter-Domain Routing)
IP 주소를 더 유연하고, 효율적으로 할당하기 위해 고안된 주소 체계
1993년부터 기존의 클래스 기반 주소 할당을 대체함
CIDR의 특징
- 가변 길이 서브넷 마스크(VLSM) 사용
- 주소 뒤에 /숫자 형태로 네트워크 크기를 표현
예: 192.168.10.0/24 - 숫자는 네트워크 비트 수를 의미 (남은 비트는 호스트용)
- 주소 뒤에 /숫자 형태로 네트워크 크기를 표현
- IP 주소 낭비 방지
- 꼭 256개 단위가 아니라 필요한 만큼만 할당 가능
예: /30 → 4개 IP만 할당 (2개 usable)
- 꼭 256개 단위가 아니라 필요한 만큼만 할당 가능
- 라우팅 테이블 주소
- 여러 네트워크를 하나로 묶어 광고 가능 (route aggregation)
192.168.0.0/24, 192.168.1.0/24 → 192.168.0.0/23
- 여러 네트워크를 하나로 묶어 광고 가능 (route aggregation)
예시) IP 주소: 192.168.10.0/26
- /26 : 네트워크 비트 26개
- 서브넷 마스크: 255.255.55.192
- 호스트 비트 수 : 6개
- 사용 가능 IP 수 : 2^6 = 62개 (2개는 네트워크 주소 & 브로드캐스트용 주소)